

Programele de recunoaștere facială fac discriminări de gen și rasă
Aplicațiile de recunoaștere a fețelor întăresc stereotipul conform căruia femeile trebuie să fie drăguțe, iar bărbații sunt liderii în afaceri.
Când cercetătorii americani și europeni au încărcat imagini cu membrii congresului american în serviciul Google de recunoaștere a imaginilor, acesta a aplicat etichete diferite bărbaților și femeilor. Dacă la bărbați cuvintele cheie au fost au fost „oficial” și „om de afaceri”, la femei etichetele aplicate erau, printre altele „zâmbet” și „bărbie”. Se poate deduce că software-ul a fost antrenat pe baze discriminatorii: programul întărește stereotipul conform căruia femeile trebuie să fie drăguțe, iar bărbații sunt liderii în afaceri.
Prejudecăți în loc de răceală matematică
Acestea sunt câteva dintre concluziile unui studiu realizat de o echipă condusă de Carsten Schwemmer, de la Institutul GESIS Leibniz pentru Științe Sociale din Köln. Echipa a colaborat cu cercetători de la New York University, American University, University College Dublin, University of Michigan și asociația California YIMBY, informează Wired.
Cercetătorii au folosit serviciul de inteligență artificială (AI) de la Google, Amazon și Microsoft. Au fost plătiți oameni care au revizuit adnotările pe care aceste servicii le aplicau fotografiilor oficiale ale parlamentarilor și imaginilor pe care aceștia le-au postat pe Twitter.
Serviciile AI au văzut, în general, lucruri pe care și recenzorii umani le-au putut vedea în fotografii, dar au avut tendința de a observa diferite lucruri despre femei și bărbați; femeile au fost mult mai susceptibile de a fi caracterizate prin aspectul lor. Membrele congresului erau adesea etichetate cu „fată” și „frumusețe”. Studiul demonstrează că algoritmii nu văd lumea cu detașare matematică, ci au tendința de a reproduce sau chiar de a amplifica prejudecățile culturale istorice.
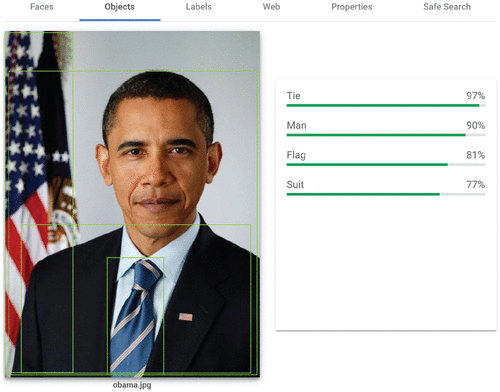
Informații oferite de platforma Cloud Vision de la Google, pentru imaginea lui Barrack Obama.
(Sursa: studiu – CC BY)
Noul studiu a fost publicat săptămâna trecută, dar cercetătorii au adunat date de la serviciile AI în 2018. Experimentele realizate de WIRED folosind fotografiile a zece bărbați și zece femei din senatul din California sugerează că rezultatele studiului sunt încă valabile.
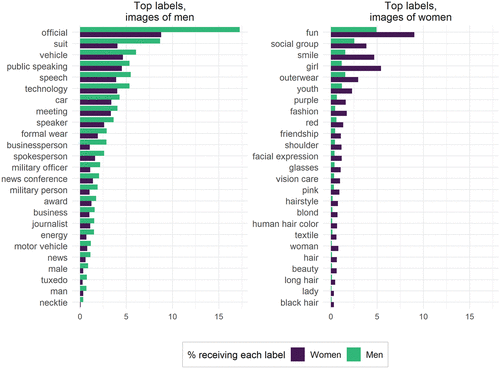
Exemple comparative de etichete aplicate de Google unor imagini cu bărbați și femei.
(Sursa: studiu – CC BY)
Aceste diferențe nu sunt noi și ele se mulează pe credințele din societatea modernă.
Problemă veche, soluții grele
Această înclinare a programelor de recunoaștere facială de a judeca diferit bărbații și femeile a fost observată încă din 2016 de către cercetători. Atunci, profesorul de informatică Vicente Ordóñez a observat un model în unele dintre presupunerile făcute de software-ul de recunoaștere a imaginilor pe care îl construia, scria Wired. Asta l-a făcut pe Ordóñez să se întrebe dacă el și alți cercetători nu cumva injectau inconștient prejudecăți în software-ul lor.
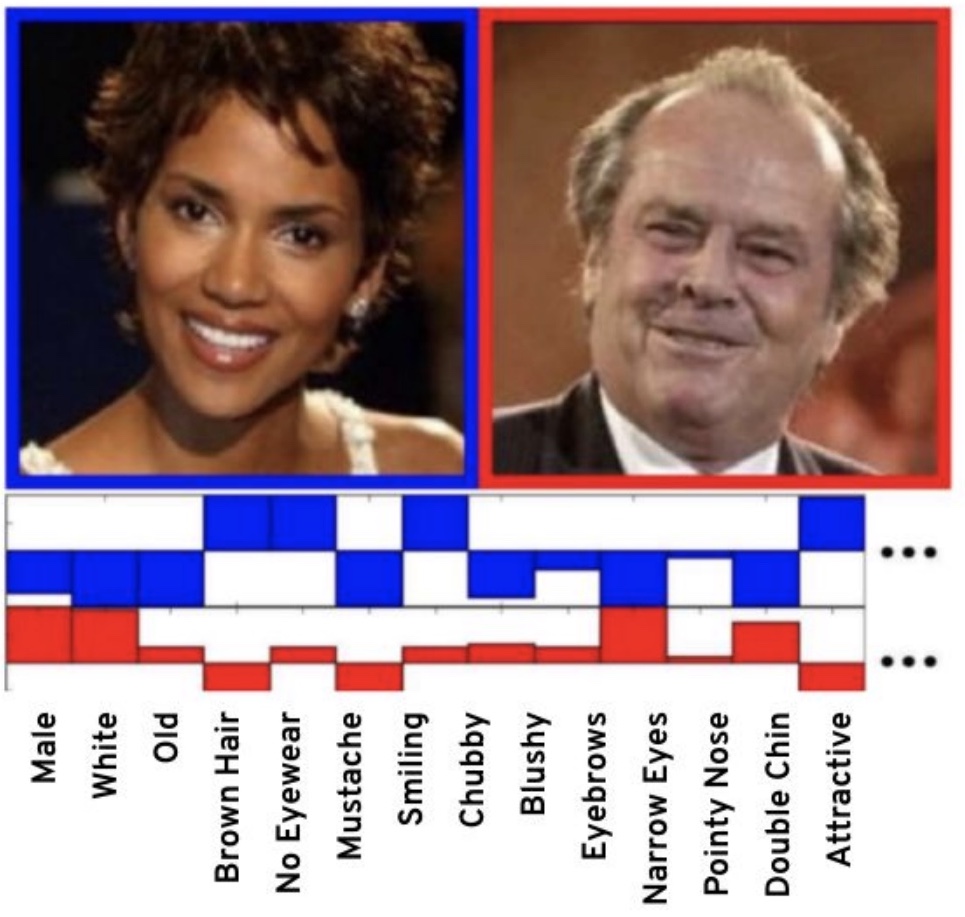
Potrivit acestei identificări automatizate, Hale Berry ar putea fi bărbat și cam la egalitate albă și neagră, dar și mult mai atractivă decât Jack Nicholson, care, de altfel, are gușă, dar este mai slab decât actrița.
(Sursa: studiu)
Două colecții de imagini de cercetare, de la Microsoft și Facebook, afișau prejudecăți de gen predictibile în descrierea activităților precum gătitul și sportul. Imaginile cu cumpărături și spălat rufe erau legate de femei, de exemplu, în timp ce sportul și fotografiatul erau legate de bărbați. Dacă un set foto asociază în general femeile cu gătitul, software-ul instruit prin studierea acelor fotografii și a etichetelor acestora creează o asociere și mai puternică.
Umbrele de gen
În 2018, proiectul Gender Shades a arătat că serviciile cloud ale companiilor Microsoft, IBM și Face++ au fost foarte precise la identificarea genului bărbaților albi, dar foarte inexacte la identificarea genului femeilor negre. La acea vreme, cercetătorii de la Massachussetts Institute of Technology s-au declarat jenați de aceste rezultate, dar au precizat că nu-și permit să ignore concluziile studiului.

Măsurători comparative din studiul Gender Shades.
(Sursa: Joy Buolamwini, CC BY-NC-ND)
Folosind sistemul de clasificare a tipului de piele Fitzpatrick, studiul a caracterizat distribuția genului și a tipului de piele pe două criterii de analiză facială. Femeile cu pielea mai închisă la culoare au avut o rată de eroare de identificare de 34,7%. Rata maximă de eroare pentru bărbații cu piele mai deschisă a fost de 0,8%.
Studiul a arătat că inteligența artificială ajută la determinarea persoanelor care vor fi angajate, concediate, cărora li se va acorda un împrumut sau chiar la stabilirea timpului pe care-l va petrece cineva în închisoare. Selectarea datelor de învățare pentru a regla fin sistemele de inteligență artificială este o parte esențială a dezvoltării unor modele predictive solide. Cu toate acestea, părtinirea care reflectă inechitățile sociale pot oferi un sentiment fals al progresului.
Foto: Gerd Altmann (Pixabay)
Faptul ca pe baza tuturor datelor disponibile AI-ul asociaza femeile cu SOCIAL GROUP inseamna ca de fapt ele se constituie ca o problema sociala, un grup neintegrat in societate.
Această dilemă a fost rezolvată încă din anii ’60. Faptul că sistemele AI încă nu recunosc cu acuratețe sporită genul unor persoane din imagini nu duce deloc la concluzia că ar fi vorba despre probleme legate de grupuri „neintegrate” (termen care denotă un puternic bias discriminatoriu).
Daca nu intelegeti cum functioneaza un algoritm de ML nu comentati aiurea. Nu sta nimeni sa faca un dataset cu bias rasial/sexist. E nevoie de seturi mari de date, cu cat sunt mai generale cu atat e mai usor sa le generezi / achizitionezi (In sensul achizitiei de date, nu al cumpararii, desi ele pot fi acelasi lucru)
ML = Operatii cu matrici. La un moment dat se scot niste eigenvalues/eigenvectors care reprezinta, intr-un limbaj foarte naiv, gradul de similaritate intre diverse elemente din setul de date si proportia in care contribuie la stabilirea trendului (daca reuseste cineva sa le explice mai bine, va rog sa o faceti, pe mine ma bat cuvintele).
Acum, normal ca daca 13 % din populatia unei tari comite 50% din infractiunile violente si pozele tind sa fie mai intunecate ca restul algoritmul o sa asocieze ceva cu ceva.
Depinde foarte mult si care e scopul pentru care se proceseaza datele, ex. un algoritm care trebuie sa diferentieze intre femei si barbati va avea alt mod de functionare/implementare fata de unul care trebuie sa faca auto-tagging la poze (cum face FB, daca te uiti la aria-label-ul asociat fiecarei imagini) si, cel mai important, alt set de date i.e. pt al doilea exemplu vor fi imagini de pe retele de socializare, de ex, unde femeile tind sa puna alt tip de poze fata de barbati, cu alte descrieri, etc. fata de primul exemplu unde imaginile vor fi generic etichetate ca „femeie”, „barbat”
In concluzie nu mai vorbiti aiurea/preluati stiri din afara de la oameni care vorbesc aiurea ca sa impingeti o agenda. Realitatea e de multe ori mai complexa.
Mulțumesc pentru comentariu și mă bucur că știți cum funcționează tot sistemul! Articolul meu nu face decât să popularizeze acest domeniu, pe înțelesul tuturor. Pentru pasionați, ca dv., există link-urile spre studiile științifice și o bibliografie mare pe acest subiect.