Gestul de a căuta ceva pe Google este astăzi atât de banal încât nici nu ne mai gândim ce efort și câtă tehnologie este în spatele lui. Dacă stăm să ne gândim, Google are în orice moment o copie a (aproape) tuturor informațiilor stocate online. Într-un gest de deschidere, compania a explicat pe blog-ul său cum face această „minune”.
Site-uri de tot felul
Evident, cea mai mare parte a rezultatelor căutării vine din „Web-ul deschis”, adică site-urile de tot felul din lume. Motoarele lui Google numite „crawlers” colindă Web-ul, indexează site-urile și le ierarhizează pe baza algoritmului său. De cele mai multe ori, Google face acest lucru urmând instrucțiunile concepute de administratorii site-urilor într-un fișier numit „robots.txt”. De aceea este bine să aveți tot timpul actualizat acest fișier în care veți preciza ce să indexeze Google și ce nu.
Un alt fișier important este „sitemap.xml”, unde există o hartă a site-ului, cu ierarhia paginilor, pe baza căreia motorul de căutare își dă seama ce pagini sunt mai importante decât altele. Astfel, zilnic, Google trimite vizitatori către peste 100 de milioane de site-uri Web diferite.
Cunoștințe comune
Creatorii, editorii și companiile creează conținut și oferă produse și servicii unice. Dar există, de asemenea, informații care se încadrează în categoria a ceea ce ați putea descrie drept cunoaștere comună – informații care nu „aparțin” niciunei persoane, ci reprezintă un set de fapte cunoscute (de exemplu: data nașterii unei figuri istorice, înălțimea celui mai înalt munte din America de Sud sau chiar ce zi este astăzi).
Google ajută oamenii să găsească cu ușurință aceste tipuri de fapte printr-o varietate de funcții, cum ar fi „panourile de cunoștințe” (knowledge panels), care se afișează în partea dreaptă a paginii rezultatelor căutării, în varianta desktop. Informațiile provin dintr-o gamă largă de surse licențiate deschis, cum ar fi: Wikipedia, Encyclopedia of Life, Johns Hopkins University CSSE COVID-19 Data și Data Commons Project.
Colaborări fructuoase
Bazele de date structurate, inclusiv bazele de cunoștințe publice precum Wikidata, fac mult mai ușor pentru sistemele lui Google să înțeleagă, să organizeze și să prezinte fapte în caracteristici și formate utile. Pentru unele tipuri de date specializate, cum ar fi scoruri sportive, informații despre emisiuni TV și filme și versuri de melodii, există furnizori organizează informațiile într-un format structurat și oferă soluții tehnice (cum ar fi API-urile) pentru a oferi date. Google licențiază datele de la aceste companii.
În cazul unor informații delicate, cum ar fi date despre sănătate și participare civică, date care afectează milioane de oameni, accesul ușor la informații fiabile este oferit de autorități locale și organizații nonpartizane și nonprofit.
Informații „cadou”
Există o gamă largă de informații care nu sunt disponibile în prezent pe Web-ul deschis, așa că Google solicită companiilor locale să-și revendice profilurile (seturi de date despre ele) și să împărtășească cele mai recente informații cu potențialii „căutători”. În fiecare lună, Google conectează persoane cu peste 120 de milioane de companii care nu au un site Web. În medie, rezultatele locale generează mai mult de patru miliarde de conexiuni pentru companii în fiecare lună, incluzând peste două miliarde de vizite pe site-uri Web.
Ca urmare a pandemiei COVID-19, Google a folosit tehnologia conversațională duplex pentru a suna companiile și a le solicita confirmarea detaliilor despre ele, cum ar fi orele de funcționare modificate sau dacă acestea oferă preluarea produselor de la sediu și livrarea la domiciliu. Astfel, s-au făcut peste trei milioane de actualizări pentru companii precum farmacii, restaurante și magazine alimentare, care au fost văzute de peste 20 de miliarde de ori în Maps și în rezultatele căutărilor.
Algoritmul de ierarhizare secret
Nu se știe în detaliu cum organizează Google informația în așa fel încât să judece importanța paginilor Web. Știm încă că sistemele de clasificare iau în considerare o serie de factori – de la ce cuvinte apar pe pagină, până la cât de nou este conținutul – pentru a determina ce rezultate sunt cele mai relevante și utile pentru o anumită interogare. Aceste sisteme se bazează pe o înțelegere profundă a informațiilor – de la limbaj și conținut vizual la context, cum ar fi timpul și locul.
{kind=link}
(Sursa: Google)
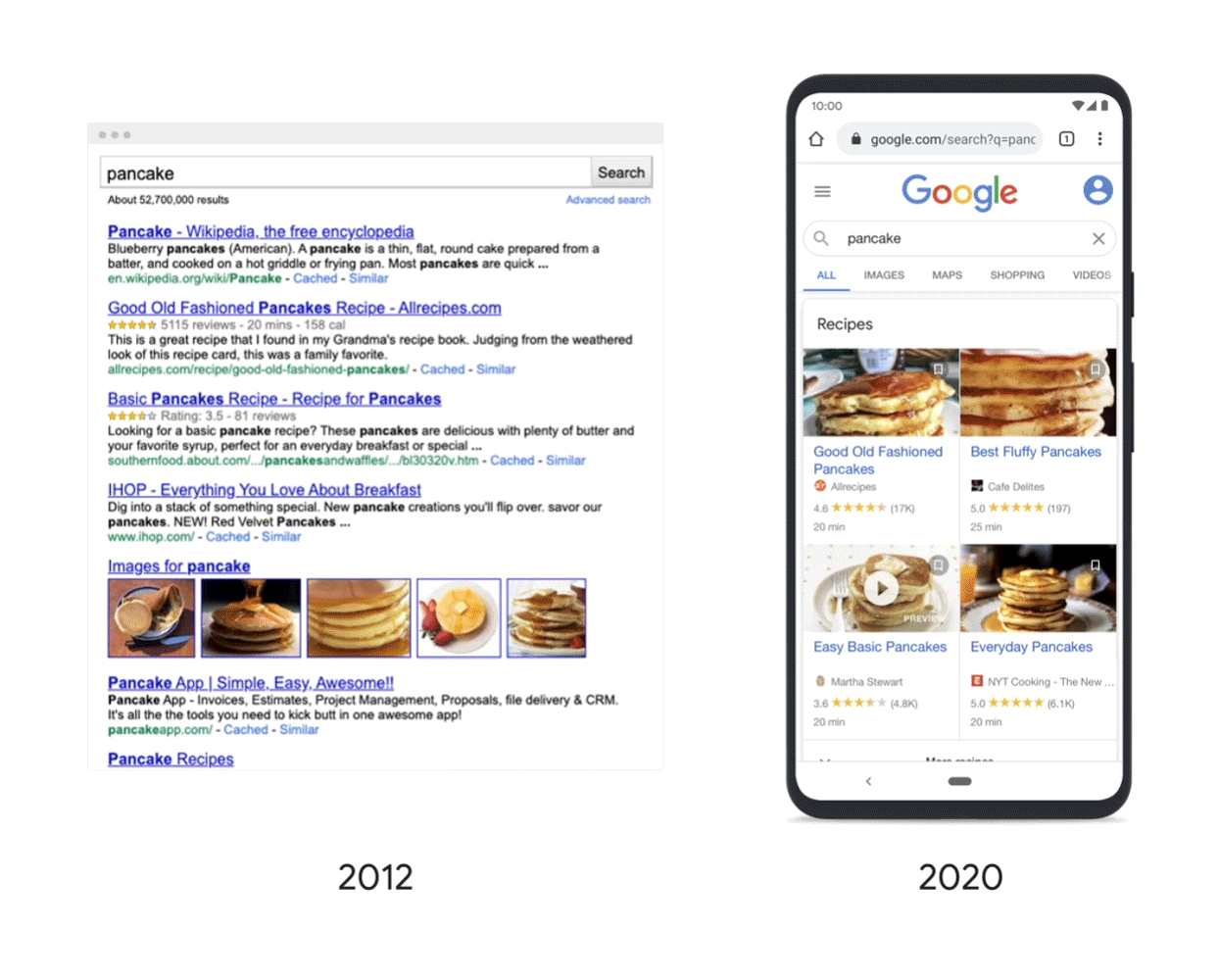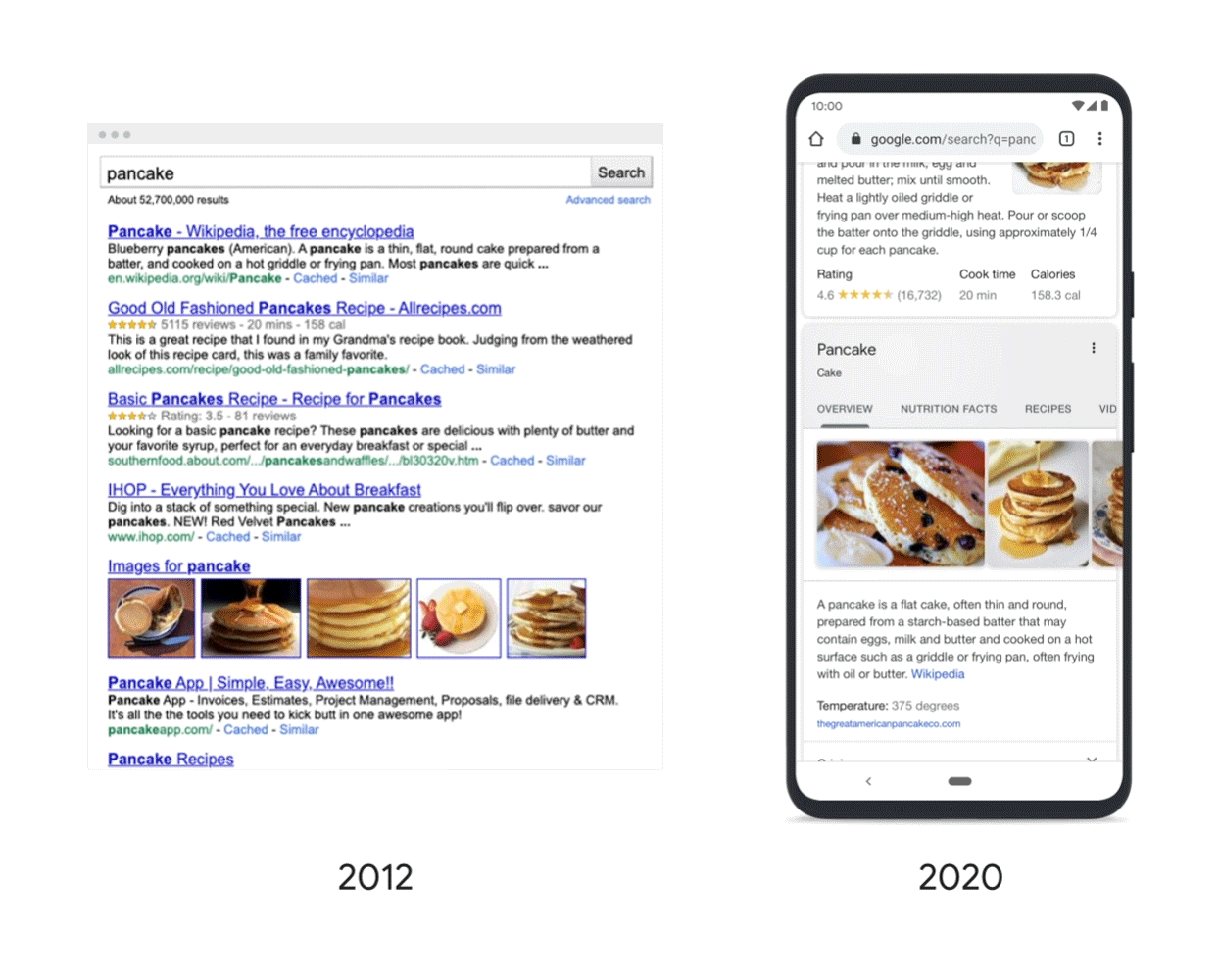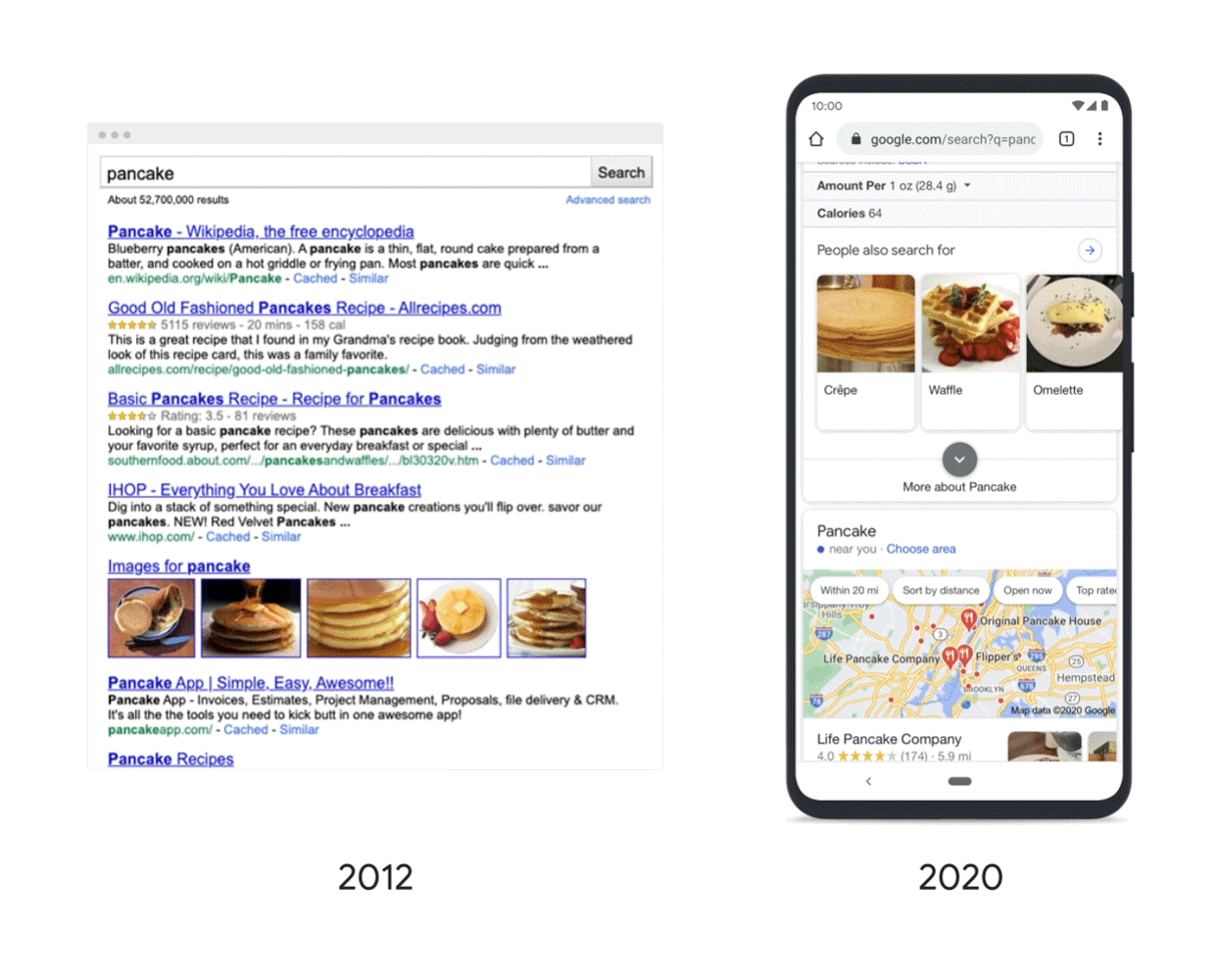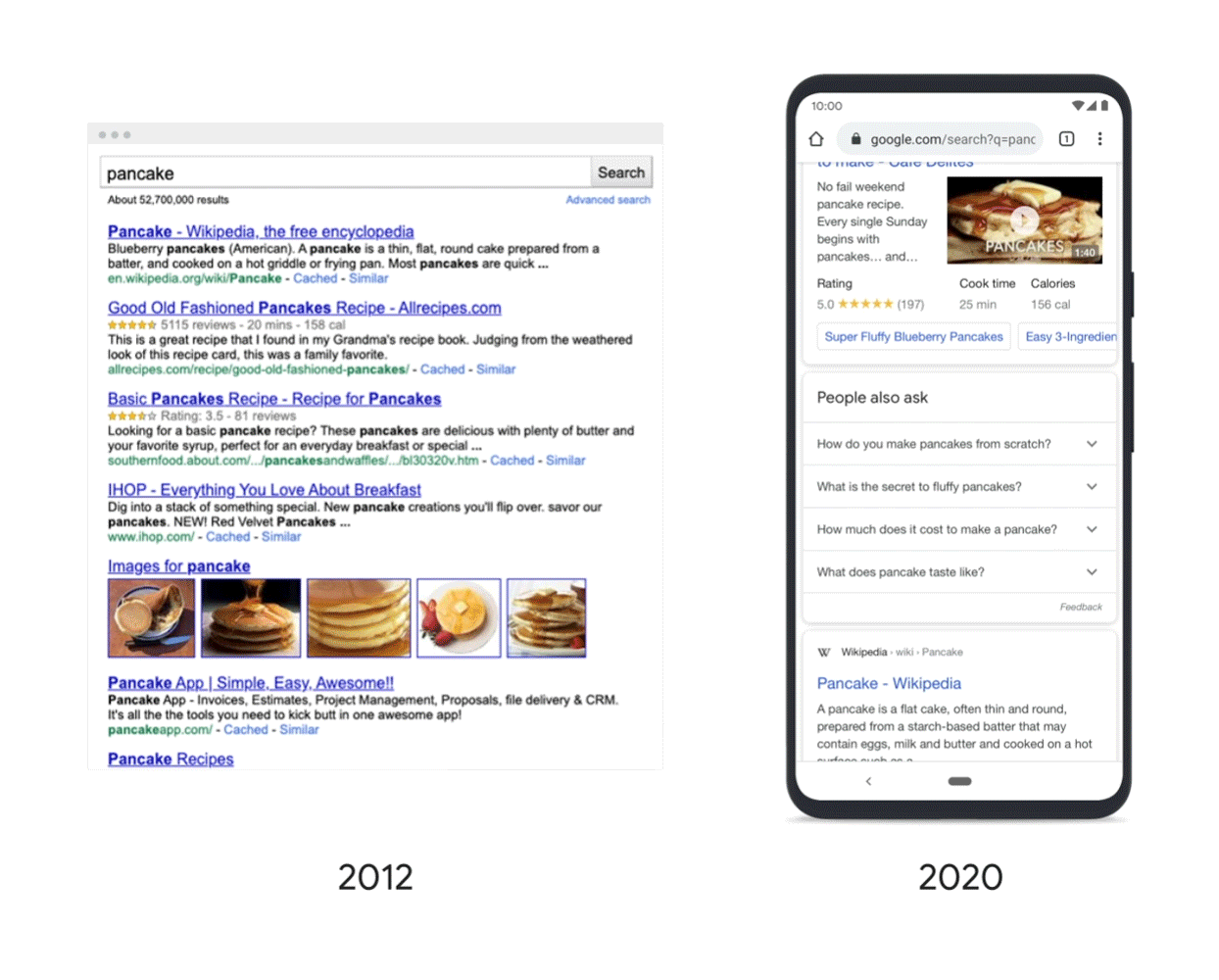
Căutați ceva practic precum „pizza” și s-ar putea să găsiți restaurante în apropiere, opțiuni de livrare, rețete de pizza și multe altele. Sistemele Google construiesc pe loc o pagină care este probabil să conțină ceea ce căutați, clasificând rezultatele, cu cele mai importante în partea de sus. Plasarea în prima jumătate a ecranului a unei rețete de pizza ar fi cu siguranță relevantă, dar sistemele Google au aflat că persoanele care caută „pizza” sunt mai susceptibile să caute restaurante, așa că este probabil să fie afișată mai întâi o hartă cu restaurantele locale.
La o interogare precum „clătită”, este mai probabil ca oamenii să caute rețete, așa că rețetele se plasează adesea mai sus, iar o hartă cu restaurante care servesc clătite poate apărea mai jos pe pagină.
Foto: Arthur Osipyan (Unsplash)
Leave a Comment